In Applications that are used by non-technical end users, which are these days very often web applications, we have to deal with the issue that an unexpected error occurs.
There are the two extremes:
We can just show a screen telling in a nice design that the application does not work and that is all. In terms of user experience that is a good approach and often the recommended way. But there is no reasonable path to recover, other than retrying.
The other extreme, which we actually see quite a lot, is this:
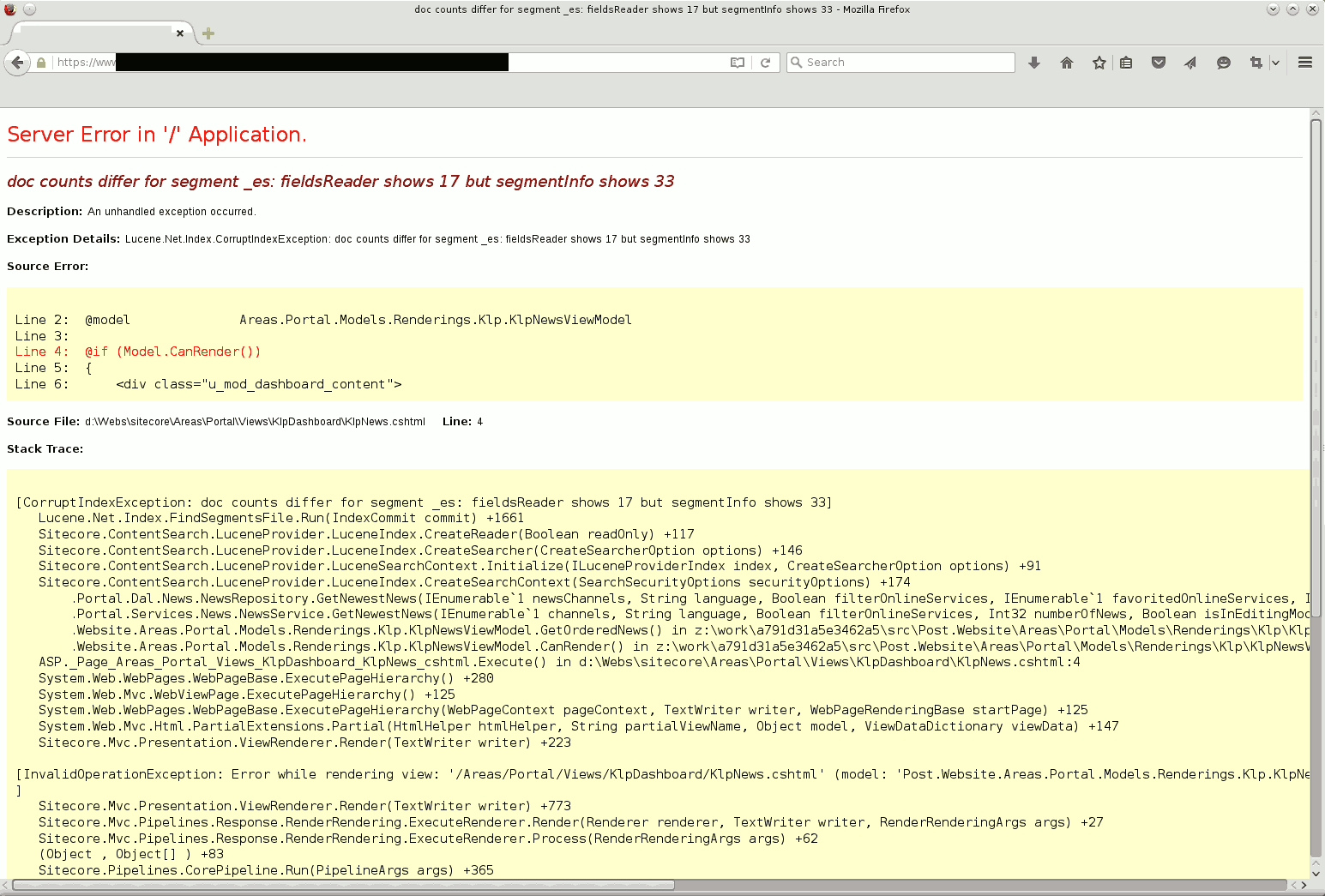
That may be ok in some rare case, during beta test or for an internal application that is only used by the development team.
This was a productive application, apparently developed in some MS-dotnet-language, most likely C# or ASP-dotnet, but the same issues are valid for PHP, Java/JSF/JEE, Ruby, Perl, Perl 6, Python, Scala, Clojure, C, C++ and whatever you like.
Imagine Google would display such information because of a bug in their search engine and there were a contact mail address or phone number and millions of people would call their call center every day with such bugs… In this case it is probably better to hide the exception from the users and probably write the software well enough that such issues do not occur too often, because too many people rely on this every day.
The other side is, that there are probably some log files and the exceptions can be found there. Now the log files can be monitored manually, which becomes a bad idea as soon as there is actually one or more full time user, because the logs become huge, but tools like grep or simple Perl scripts or tools like splunk can help to deal with this. Since applications tend to be distributed, we have to deal with the fact that the same single instance of error and even more so the same kind of error will occur in many different logs and we need to match them to make sense of this and to understand the problem.
Reading logs and especially stack traces is especially hard in framework worlds, where there are hundreds of levels in the stacktraces coming from the frameworks. Often this is were the error actually is, but even more often it is the application and anyway we are more comfortable doing an workaround rather than fixing the framework, which we could do at least if it is open source. And we should actually send a bug report with as much information as possible, but avoid interpretation on what the bug could be. This can be added as a comment to the bug report, maybe even with a hint how to fix it or a patch, but it should be kept separate.
Anyway, usually we assume the error is not in the framework and this is usually true. So it is a challenge to read this and again tools or scripts should be used to do this. It is also possible and usually necessary to find occurrences of the same kind of error. Often this is hard, because the root cause does not manifest itself and we get consequential errors much later. That is why we are IT experts, so we can find even such hidden bugs. 🙂
Now it is possible to make life a little bit easier. We can give exceptions unique IDs, that can be something like this:
eeeeee-cccc-hhhh-tttttttt-ttttttttt-nnnnnnnnn
where each block consists of digits and upper case letters.
eeeeee encodes the type of the exception, for example by skipping all lower case letters. It does not have to be perfect, just give a hint.
cccc is an error-code if this is used. If and when exceptions should include error codes is an interesting issue by itself.
hhhh is encodes the host where it originally occurred.
tttt… is the time-stamp. If we use msec since 1970 and use base 36 to encode it, it can be shorter.
nnnn… is a number from some counter.
This is just an idea. You could use UUIDs or do something along these lines, but different. Using base 36 is actually a good idea, it makes these codes shorter.
Anyway, having such an ID in each exception in the log allows more easily to find which are different log entries for exactly the same exception. And yes, they do occur and that is OK. Such a code could also be displayed on the screen of the end user if it is an application where users actually have access and contact to some support team. Then they can read it. Again, aim to make it short and unique, but don’t make the whole mechanism too fragile, otherwise we deal with finding the exceptions in the exception handling framework itself and that is not desirable.
What is important: We should actually fix bugs, when we find them. Free some time for it, write unit tests that prove the bug, fix it and make sure it does not come up again by retaining the unit test. Yes, it is work but it is worth it. If the bug justifies an immediate deployment or if we have to wait for a deployment window is another issue, but it should be fixed at least with the next deployment. If regular deployments should be done twice a year or daily is an interesting issue by itself. There should always be ways to do an „emergency deployment“ in case of a critical bug, but it is good to have strong regular mechanism so the emergency deployment can remain an exception.
