The goal of spline approximation has already been explained in the previous article „Spline Approximation (Introduction)„.
This article will cover the mathematics behind this approximation and develop an approach. If you do not care about the mathematics, just skip this article and read the Spline Approximation (Cookbook)“, that will come soon.
Spline Interpolation
We have points
![\[(x_0, y_0), (x_1, y_1), \ldots, (x_n, y_n)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-32c169ca08aa1d049a00f14b699f82cb_l3.svg "Rendered by QuickLaTeX.com")
(0.1) ![\[x_0 < x_1 < x_2 < \ldots < x_n \]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-0a3c30648d4199dfa4cd9c99a5af847f_l3.svg "Rendered by QuickLaTeX.com")
and want a function f such that
![\[(1)\thickspace \bigwedge_{i=0}^n f(x_i) = y_i\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-11ef934755ef20d90672f2cdd4528ed0_l3.svg "Rendered by QuickLaTeX.com")
and f is continuous. Usually the requirement goes further, so the first and second derivative should also be continuous too.
The way this is accomplished is by defining cubic polynomials  on each interval
on each interval ![[x_j, x_{j+1}]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-9170d120d3644c7c3e080b0a1b07097a_l3.svg "Rendered by QuickLaTeX.com") such that
such that
![\[(2)\thickspace \bigwedge{j=1}^{n-1} f'_{j-1}(x_j)=f'_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-50060ad10581e671c571893722219ca1_l3.svg "Rendered by QuickLaTeX.com")
![\[(3)\thickspace \bigwedge{j=1}^{n-1} f''_{j-1}(x_j)=f''_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1b3995a80dc50ee928088055a9e715bd_l3.svg "Rendered by QuickLaTeX.com")
Now this gives us  unknowns and together with the initial condition
unknowns and together with the initial condition  equations. So this is underdetermined, which is usually resolved by adding two more or less arbitrary conditions. A lot of material can be found about this in the internet, in papers and in books.
equations. So this is underdetermined, which is usually resolved by adding two more or less arbitrary conditions. A lot of material can be found about this in the internet, in papers and in books.
Spline Approximation
Now a more interesting case is that we actually have much more given points than spline intervals. So we have interval borders at points
![\[x_0,\ldots,x_n\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-459d49cc184ac7cf03b0250358be0af2_l3.svg "Rendered by QuickLaTeX.com")
and we have given pairs
![\[(\xi_1,\eta_1), \ldots, (\xi_N, \eta_N)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-6c65f742eac20d06d9ae99bd3c9c7a41_l3.svg "Rendered by QuickLaTeX.com")
with  much larger than
much larger than  . The exact condition will become clear later, but for the time being it should be assumed, that is meant to be much larger than . The values
. The exact condition will become clear later, but for the time being it should be assumed, that is meant to be much larger than . The values  may contain duplicates, but in that case the number of different values for should also be much larger than .
may contain duplicates, but in that case the number of different values for should also be much larger than .
Btw. this is nothing new. Papers about this topic exist, but it is not as commonly found on the internet as the interpolation.
From here onwards, it is assumed, that the intervals all have the same length, i.e. there is some positive real number  such that
such that  for all
for all  .
.
So we want the conditions (2) and (3) to be fullfilled and a weaker condition
![\[(1a)\thickspace \bigwedge_{j=1}^{n-1} f_{j-1}(x_j)=f_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1475a72285388d1115fa6269fdead5c4_l3.svg "Rendered by QuickLaTeX.com")
and we want  to be „somewhat close“ to
to be „somewhat close“ to  for all points
for all points  . More precisely it should be as close as possible on „average“, where the quadratic mean is used as „average“. That is common practice, allows for smooth formulas and works. To just minimize the quadratic mean, taking the square root and dividing by can be ommitted. So this can be made explicit by requiring the sum of the squares of the differences to be minimal i.e.
. More precisely it should be as close as possible on „average“, where the quadratic mean is used as „average“. That is common practice, allows for smooth formulas and works. To just minimize the quadratic mean, taking the square root and dividing by can be ommitted. So this can be made explicit by requiring the sum of the squares of the differences to be minimal i.e.
![\[(4)\thickspace \sum_{i=1}^N (f(\xi_i)-\eta_i)^2 \text{ is minimal}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1ae2ac7ff8a4251beb4a66401e4ee123_l3.svg "Rendered by QuickLaTeX.com")
Btw. this can be done perfectly well with complex valued functions, we just need to replace the squares by the squares of the absolute values. So on the „ -side“ we can have complex numbers. Allowing complex numbers on the „
-side“ we can have complex numbers. Allowing complex numbers on the „ -side“ is a bit more involved, because being differentiable twice implies that the function would be holomorphic, so combining different functions is impossible. And even complex valued functions would become non continuous at the glue lines if we simply apply them to the whole complex plain. So, for the time being, real numbers are assumed.
-side“ is a bit more involved, because being differentiable twice implies that the function would be holomorphic, so combining different functions is impossible. And even complex valued functions would become non continuous at the glue lines if we simply apply them to the whole complex plain. So, for the time being, real numbers are assumed.
Now the valid spline functions on the given set of intervals obviously form a vector space. Conditions (1a), (2) and (3) remain valid when we multiply by a constant or add two such functions. Having parameters and  independent conditions, its dimension should be
independent conditions, its dimension should be  . This can be proved by induction. For
. This can be proved by induction. For  any cubic polynomial (of degree
any cubic polynomial (of degree  ) can be used. These form a 4-dimensional vectorspace. Assuming that for subintervals the valid spline functions form a vector space of dimension , then for
) can be used. These form a 4-dimensional vectorspace. Assuming that for subintervals the valid spline functions form a vector space of dimension , then for  subintervals the additional subinterval
subintervals the additional subinterval ![[x_n, x_{n+1}]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-85c5feea1d5351a816d202be772d3379_l3.svg "Rendered by QuickLaTeX.com") is added. In this subinterval, the function can be expressed as
is added. In this subinterval, the function can be expressed as
![\[f(x)=a+b(x-x_n)+c(x-x_n)^2+d(x-x_n)^3\text{.}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-eca131d3d6f98c8881f85a0811eab1f7_l3.svg "Rendered by QuickLaTeX.com")
Conditions (1a), (2) and (3) already fix the values for  ,
,  and
and  , while
, while  can be choosen freely. Thus the dimension is exactly one higher and the assumption is proved.
can be choosen freely. Thus the dimension is exactly one higher and the assumption is proved.
Now a basis for this vector space should be found. Ideally functions that are only non-zero in a small range, because they are easier to handle and easier to calculate.
This can be accomplished by a function that looks like this:
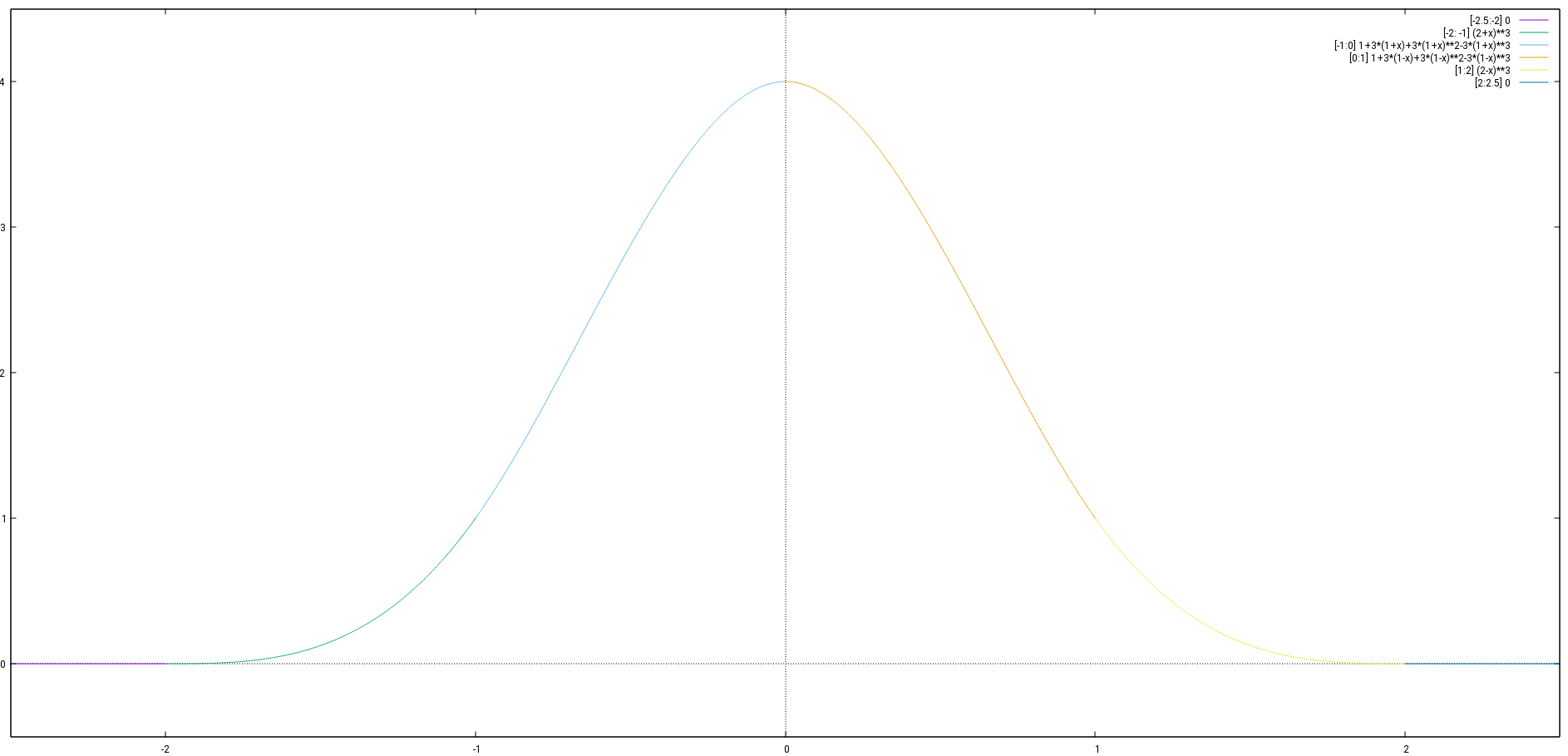
Note that this is not the Gaussian function curve, which never actually becomes zero. The function we are looking for should actually be 0 outside of a given range. So assuming it is  for
for  and
and  for
for  for some constant
for some constant  . This implies that the first and second derivative are
. This implies that the first and second derivative are  for
for  . So in the subinterval starting at
. So in the subinterval starting at  it needs to be a cubic polynomial of the form
it needs to be a cubic polynomial of the form  . So further subintervals are needed to return to . For reasons of symmetry there should be a subinterval ending at
. So further subintervals are needed to return to . For reasons of symmetry there should be a subinterval ending at  in which the function takes the form
in which the function takes the form  . Using a third subinterval
. Using a third subinterval ![[-B, B]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7930e5eb60b08c9c79feaad5515fd0f2_l3.svg "Rendered by QuickLaTeX.com") for the whole middle part would imply that this has to be an even function, thus of the form
for the whole middle part would imply that this has to be an even function, thus of the form  . could be determined as
. could be determined as  . According to the first derivative condition we would have
. According to the first derivative condition we would have  , thus
, thus  . According to the second derivative condition we would have
. According to the second derivative condition we would have  thus
thus  thus
thus  Since subintervals of equal length are required, this is not adequate.
Since subintervals of equal length are required, this is not adequate.
Using a total of four subintervals actually works. In this case for the subinterval ![[-B,0]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-c59f71baddbaa30543b1b944b6f50145_l3.svg "Rendered by QuickLaTeX.com") four conditions are given to determine the four coefficients of the cubic function.
four conditions are given to determine the four coefficients of the cubic function.
For readability it will be assumed that  and
and  , so the subintervals are
, so the subintervals are ![[-2,-1], [-1, 0], [0,1], [1,2]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-8c248cc84442b6ce9d8537b03ba10fb4_l3.svg "Rendered by QuickLaTeX.com") . The function can be choosen as
. The function can be choosen as
![\[f(x)= \begin{cases} 0 &\text{for } x \le -2\\ (x+2)^3&\text{for } -2 < x \le -1 \end{cases}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-a79f1ad5e116a795d2904680555c3fb5_l3.svg "Rendered by QuickLaTeX.com")
Now
![\[f(x)=a+b(x+1)+c(x+1)^2+d(x+1)^3\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-60abf1bcd8b868329e6e18c77fb6d68f_l3.svg "Rendered by QuickLaTeX.com")
needs to be defined in [-1, 0] such that
![\[f(-1)=1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-50cd8f9adfb3dffd8229cd8bdb600540_l3.svg "Rendered by QuickLaTeX.com")
![\[f'(-1)=3\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7cf33adcb11b81ef5d745734a1530b8e_l3.svg "Rendered by QuickLaTeX.com")
![\[f''(-1)=6\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-4461fd6ce1b6137c0fd9127e2646359a_l3.svg "Rendered by QuickLaTeX.com")
![\[f'(0)=0\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-c1b4b8ca1bb4565af9498a89d1343753_l3.svg "Rendered by QuickLaTeX.com")
Thus  ,
,  ,
,  and
and
![\[0=f'(0)=b+2c+3d=9+3d\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-8e441ece29deb593535ba3452aee6aaf_l3.svg "Rendered by QuickLaTeX.com")
Thus  .
.
So the prototype function is
![\[(5)\thickspace f(x)= \begin{cases} 0 &\text{for } x \le -2\\ (x+2)^3&\text{for } -2 < x \le -1\\ 1+3(x+1)+3(x+1)^2-3(x+1)^3&\text{for } -1 < x \le 0\\ 1+3(1-x)+3(1-x)^2-3(1-x)^3&\text{for } 0 < x \le 1\\ (2-x)^3&\text{for } 1 < x \le 2\\ 0&\text{for } x > 2 \end{cases}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-3016030c2282c86f17796da83d572dab_l3.svg "Rendered by QuickLaTeX.com")
A base for this vector space can be found using functions  for
for  . For readability purposes we define
. For readability purposes we define
![\[x_{j}=x_0+jh\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-97ec24e7534a83386241ba47d28d3f5d_l3.svg "Rendered by QuickLaTeX.com")
even for negative  and
and  .
.
The functions are defined such that such that
![\[f_i(x)=f\left(\frac{x-x_i}{h}\right) \text{ for } i=-1,\ldots,n+1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-97cf02e77f5cf9de178083b2f6a4a067_l3.svg "Rendered by QuickLaTeX.com")
These functions fulfill conditions (1a), (2) and (3), because they inherit that from  .
.
By induction it can be proved that they are linear independent. It is true for  alone. If it is true for
alone. If it is true for  it is also true for
it is also true for  , because
, because
![\[f_i\left(x_i+\frac{3}{2}h\right) >0\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1df4b41feba4d395bca5c7b9b6939fce_l3.svg "Rendered by QuickLaTeX.com")
and
![\[\bigwedge_{j=-1}^{i-1}f_j\left(x_i+\frac{3}{2}h\right)=0\text{.}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-6646e1d1389098fe5d29501c211ef056_l3.svg "Rendered by QuickLaTeX.com")
Since
![\[\{f_{-1},\ldots,f_{n+1}\}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-316e27da42a2d48a02137edfec022533_l3.svg "Rendered by QuickLaTeX.com")
contains exactly elements, it is a vector space basis.
That means that we are searching for a function
![\[(6)\thickspace g(x) = \sum_{i} a_i f_i(x)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-d507403f3f41bebca4fae179cd78b083_l3.svg "Rendered by QuickLaTeX.com")
such that the minimality condition (4) holds.
This is accomplished by filling (6) into (4) and calculating the partial derivatives with respect to each  :
:
![\[(4a)\thickspace S(a_{-1},\ldots,a_{n+1}) = \sum_{j=1}^N \left(g\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1a630c92c038952615dd2784a664c4df_l3.svg "Rendered by QuickLaTeX.com")
![\[= \sum_{j=1}^N ( \sum_{i} a_i f_i(\xi_j)-\eta_j)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-aea6e68753f0a767a60d6445bb6e91b3_l3.svg "Rendered by QuickLaTeX.com")
Thus
![\[(4b) \thickspace\bigwedge_{k=-1}^{n+1} 0 &= \frac{\partial}{\partial a_k}\sum_{j=1}^N \left(g\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-d3c4f4b24686b37c9920d4223b0a8f7f_l3.svg "Rendered by QuickLaTeX.com")
![\[= \frac{\partial}{\partial a_k}\sum_{j=1}^N \left( \sum_{i} a_i f_i\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-2e6ed162c1bb99de05d819a2ca32e5b7_l3.svg "Rendered by QuickLaTeX.com")
![\[=\sum_{j=1}^N \left(2 f_k\left(\xi_j\right)\left( \sum_{i} a_i f_i\left(\xi_j\right)-\eta_j\right)\right)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-707f6ba540cec8d75ff113be4ad3db08_l3.svg "Rendered by QuickLaTeX.com")
![\[=2\sum_{i} a_i \sum_{j=1}^N f_k\left(\xi_j\right)\left( f_i\left(\xi_j\right)-2\sum_{j=1}^N \f_k\left(\xi_j\right)\eta_j\right)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-542698ed80f083d5804008bf19a3fc4e_l3.svg "Rendered by QuickLaTeX.com")
So it comes down to solving the linear equation system
![\[\sum_{i=-1}^{n+1} a_i \sum_{j=1}^N f_k\left(\xi_j\right) f_i\left(\xi_j\right) = \sum_{j=1}^N f_k\left(\xi_j\right)\eta_j\thickspace\text{ ~ for }k=-1,\ldots,n+1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7cb052ba2c92ee43cab7c2a29862a1e5_l3.svg "Rendered by QuickLaTeX.com")
This can be solved using a variant of the Gaussian elimination algorithm. Since this is a numerical problem, it is important to deal with the issue of rounding. Generally it is recommended choosing the pivot element wisely.
In this case the approach is chosen to iterate through the columns. For each column the line is chosen, in which the element in that column has the largest absolute value relative to the cubic mean of the absolute values of the other entries in the line.
When actually using the spline function a lot, it is probably a good idea to consolidate the linear combinations of different s within each subinterval into a cubic polynomial of the form
![\[f(x)=a+b(x-A)+c(x-A)^2+d*(x-A)^3.\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-45cb4fe7dcf9ccbb4ec91697f9d6df6b_l3.svg "Rendered by QuickLaTeX.com")
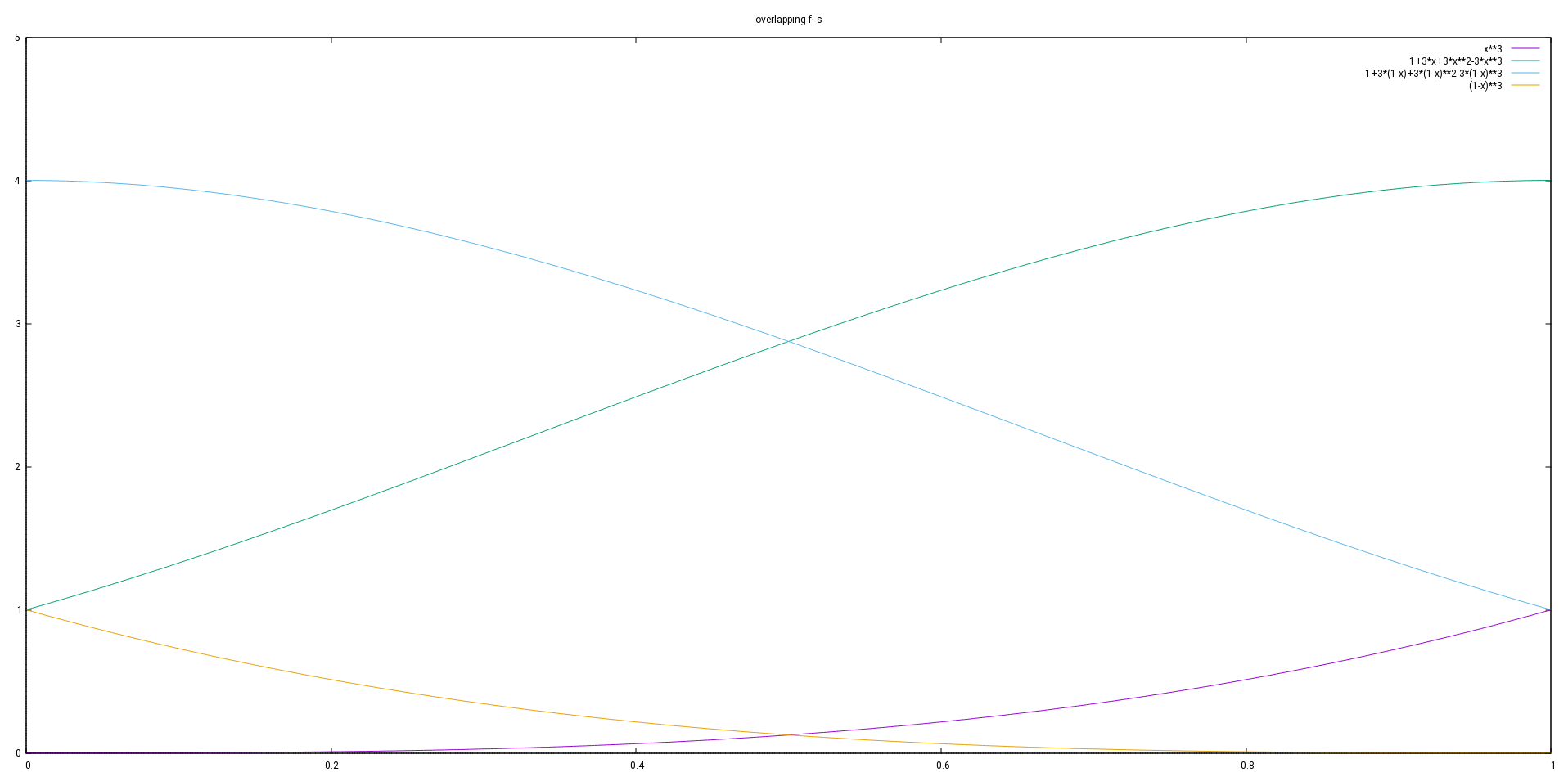
This can be based on the starting point of the interval or the end point or some point in the middle, probably the arithmetic mean of the interval borders. These choices of A have some advantages, because it makes the terms that need to be added smaller in terms of absolute value. Since the accurate end result is anyway the same, this helps avoiding rounding errors, that can go terribly wrong when adding (or subtracting) terms with large absolute values where the result is much smaller than the terms. So the arithmetic mean of the subinterval borders might be the best choice.
The actual formulas and a program will be added in one or two articles in the near future.
Links
- Spline
- Practical spline approximation (paper summary)
- Spline Approximation of Functions and Data (book chapter)</a
- Spline approximation</a
- Which pivot to solve linear systems?</a
- Spline Approximation Part 1: Basic Methodology

Schreibe einen Kommentar