When programming in Java, it is kind of part of the language to write classes with attributes and equip these attributes with „getters“ and „setters“. You could do otherwise, but you just don’t. But some criticism is of course allowed. Even if it only applies to the design of future languages or to minor improvements in the Java language.
The reason for using this pattern is of course that we do not want to impose inner implementation details of classes, but just interfaces. The implementation can change, for example the getter can caclulate the attribute instead of just returning it. Or it might possible happen in the future, that it will be calculated. And the setter can perform sanity checks or even to some adjustments of dependent attributes. Or, most interestingly, the setter can be omitted in an approach towards immutability. Now there are whole big categories of classes in many projects, that never ever contain any business logic. It is an architectural decision, to put all business logic into certain places. This does not sound like the idea of the OO-paradigm, actually Martin Fowler considers even it an antipattern, but it is done and it makes sense for classes that contain data in interface definitions. So, a typical java application has tons of layers, each with the almost same data classes, mostly without any business logic, because the business logic resides in classes that are reserved to contain business logic. Basically procedural programming, but with cool frameworks and OO because written in an OO-language. Data is copied multiple times between the different layers. One of the layers is the DB-layer and the classes are managed by hibernate. Now interesting questions arise, if hibernate goes through the getters and setters or directly to the attributes. The latter seems to be more common and it allows for a work-around for an important Oracle Bug.
Now „stupid“ getters and setters make the code larger, harder to maintain and harder to read. They can be generated automatically by IntelliJ, Eclipse, Perl Scripts or Emacs-Lisp code and I have always done it that way. But when changing code it becomes more difficult at some point.
There is also a subtle issue in terms of the name space. It is highly unusual to start attribute names with „get“ or „set“, but it would be possible and create a lot of confusion. Since getters for boolean attributes often start with „is“ or even „has“ instead of „get“, this problem does actually exist there, because people like to naturally name some boolean attributes with names like „isNew“ or „hasEngine“ and then the getters become „isIsNew“, „isHasEngine“ or something like that. Also some funny effects can occur when all capital abreviations like HTML or XML are part of the attribute name. This causes some pain, but of course, we live with it…
Interestingly Java creates „internal“ getters and setters for each attribute and they are called when accessing attributes and they are used as hooks for Hibernate in some setups. So there is seemingly an indirection too much, because the getter that we write calls the internal getter, so why not just make get… an alias for the internal getter? This does not seem to be a problem, because the optimization of Java is so fantastic and it is fair to assume that such a common case is really well optimized. So, do not mess around with this for the sake of optimazation, unless you really know what you are doing and run serious benchmarks for this.
Now having a look at other languages shows that things can be done in a better way without losing the original benefit of getters and setters.
Ruby, Scala and C# show that this is possible. The getters are just named like we would name an attribute, so we can use something like
point.x
to access the x-coordinate of the point. In Scala it is quite a thing that the classes should be immutable, so the setters go away anyway. C# and Ruby allow setters to be defined in such a way that they look like an assignment:
point.x = 9
Just two final remarks:
Do not write Unit-Tests for trivial getters and setters, but do write Unit-Tests for getters and setters that are not trivial, but have at least a bit of logic. And configure your sonarqube to be happy with that.
And in terms of documentation, if the project encourages documentation, agree on where to write the documentation and write it in this one place. For example always write javadoc for the getter and never for the attribute or the other way round. And for tons of class hierarchies that are more or less isomorphic, agree in which layer the documentation goes and write it only there, unless another layer happens to actually differ in a non-trivial way on this attribute. Having documentation for basically the same thing more than once is usually a bad idea. The burden of maintenance will increase and it will be outdated even faster than usual javadoc.
Links
- Getter und Setter (similar article in German)
- Object Creation: Builder vs. Constructor vs. Setter
- MapStruct
- Documentation
- Laziness
- Collections and Multithreading
- Oracle bug with empty stings
- Anemic Domain Model (Wikipedia)
- Anemic Domain Model (Martin Fowler)
- Mutator Method

![\[(x_0, y_0), (x_1, y_1), \ldots, (x_n, y_n)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-32c169ca08aa1d049a00f14b699f82cb_l3.svg "Rendered by QuickLaTeX.com")
![\[x_0 < x_1 < x_2 < \ldots < x_n \]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-0a3c30648d4199dfa4cd9c99a5af847f_l3.svg "Rendered by QuickLaTeX.com")
![\[(1)\thickspace \bigwedge_{i=0}^n f(x_i) = y_i\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-11ef934755ef20d90672f2cdd4528ed0_l3.svg "Rendered by QuickLaTeX.com")
 on each interval
on each interval ![[x_j, x_{j+1}]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-9170d120d3644c7c3e080b0a1b07097a_l3.svg "Rendered by QuickLaTeX.com") such that
such that![\[(2)\thickspace \bigwedge{j=1}^{n-1} f'_{j-1}(x_j)=f'_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-50060ad10581e671c571893722219ca1_l3.svg "Rendered by QuickLaTeX.com")
![\[(3)\thickspace \bigwedge{j=1}^{n-1} f''_{j-1}(x_j)=f''_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1b3995a80dc50ee928088055a9e715bd_l3.svg "Rendered by QuickLaTeX.com")
 unknowns and together with the initial condition
unknowns and together with the initial condition  equations. So this is underdetermined, which is usually resolved by adding two more or less arbitrary conditions. A lot of material can be found about this in the internet, in papers and in books.
equations. So this is underdetermined, which is usually resolved by adding two more or less arbitrary conditions. A lot of material can be found about this in the internet, in papers and in books.![\[x_0,\ldots,x_n\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-459d49cc184ac7cf03b0250358be0af2_l3.svg "Rendered by QuickLaTeX.com")
![\[(\xi_1,\eta_1), \ldots, (\xi_N, \eta_N)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-6c65f742eac20d06d9ae99bd3c9c7a41_l3.svg "Rendered by QuickLaTeX.com")
 much larger than
much larger than  . The exact condition will become clear later, but for the time being it should be assumed, that
. The exact condition will become clear later, but for the time being it should be assumed, that  may contain duplicates, but in that case the number of different values for
may contain duplicates, but in that case the number of different values for  such that
such that  for all
for all  .
.![\[(1a)\thickspace \bigwedge_{j=1}^{n-1} f_{j-1}(x_j)=f_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1475a72285388d1115fa6269fdead5c4_l3.svg "Rendered by QuickLaTeX.com")
 to be „somewhat close“ to
to be „somewhat close“ to  for all points
for all points  . More precisely it should be as close as possible on „average“, where the
. More precisely it should be as close as possible on „average“, where the ![\[(4)\thickspace \sum_{i=1}^N (f(\xi_i)-\eta_i)^2 \text{ is minimal}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1ae2ac7ff8a4251beb4a66401e4ee123_l3.svg "Rendered by QuickLaTeX.com")
 -side“ we can have complex numbers. Allowing complex numbers on the „
-side“ we can have complex numbers. Allowing complex numbers on the „ -side“ is a bit more involved, because being differentiable twice implies that the function would be holomorphic, so combining different functions is impossible. And even complex valued functions would become non continuous at the glue lines if we simply apply them to the whole complex plain. So, for the time being, real numbers are assumed.
-side“ is a bit more involved, because being differentiable twice implies that the function would be holomorphic, so combining different functions is impossible. And even complex valued functions would become non continuous at the glue lines if we simply apply them to the whole complex plain. So, for the time being, real numbers are assumed. independent conditions, its dimension should be
independent conditions, its dimension should be  . This can be proved by induction. For
. This can be proved by induction. For  any cubic polynomial (of degree
any cubic polynomial (of degree  ) can be used. These form a 4-dimensional vectorspace. Assuming that for
) can be used. These form a 4-dimensional vectorspace. Assuming that for  subintervals the additional subinterval
subintervals the additional subinterval ![[x_n, x_{n+1}]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-85c5feea1d5351a816d202be772d3379_l3.svg "Rendered by QuickLaTeX.com") is added. In this subinterval, the function can be expressed as
is added. In this subinterval, the function can be expressed as![\[f(x)=a+b(x-x_n)+c(x-x_n)^2+d(x-x_n)^3\text{.}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-eca131d3d6f98c8881f85a0811eab1f7_l3.svg "Rendered by QuickLaTeX.com")
 ,
,  and
and  , while
, while  can be choosen freely. Thus the dimension is exactly one higher and the assumption is proved.
can be choosen freely. Thus the dimension is exactly one higher and the assumption is proved.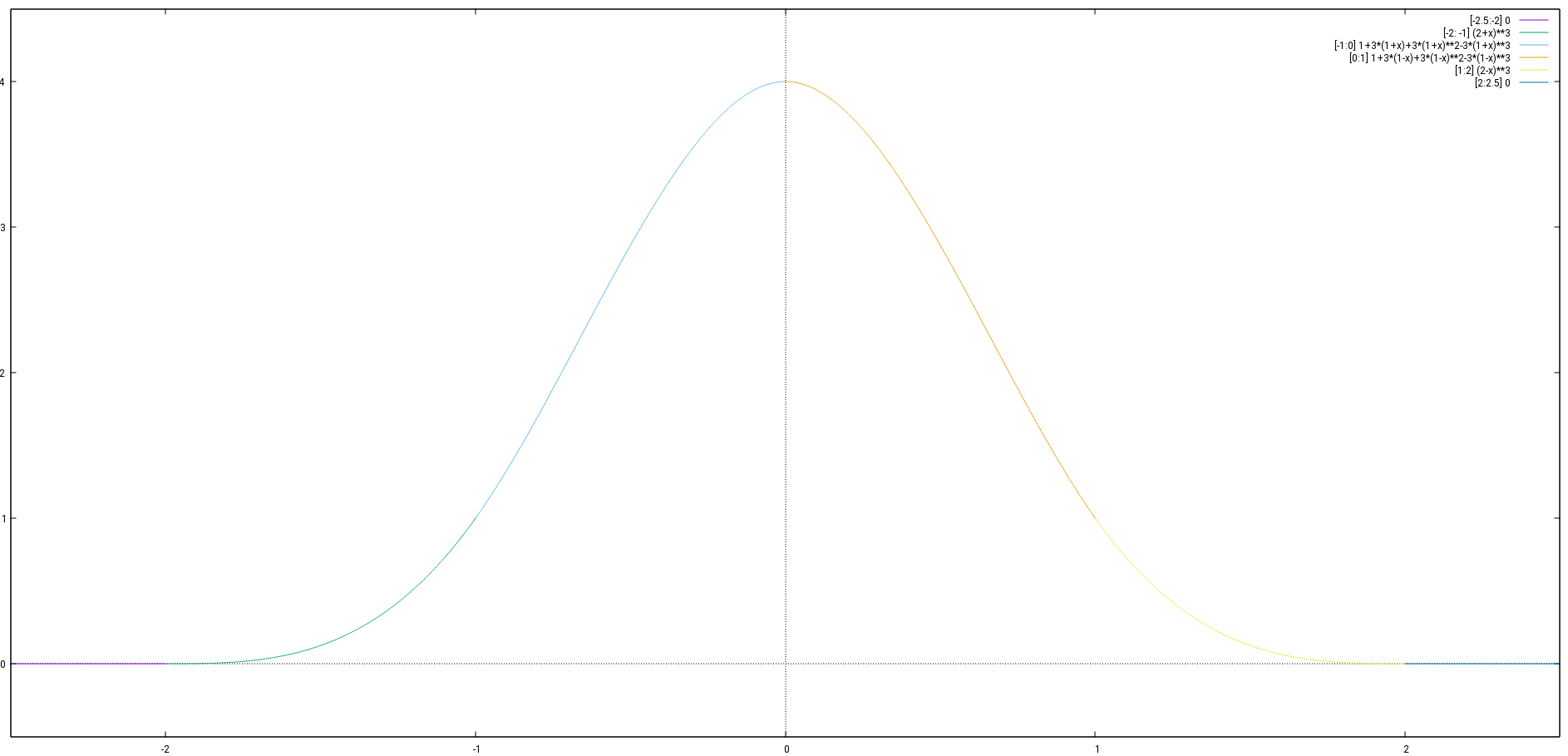
 for
for  and
and  for
for  for some constant
for some constant  . This implies that the first and second derivative are
. This implies that the first and second derivative are  for
for  . So in the subinterval starting at
. So in the subinterval starting at  it needs to be a cubic polynomial of the form
it needs to be a cubic polynomial of the form  . So further subintervals are needed to return to
. So further subintervals are needed to return to  in which the function takes the form
in which the function takes the form  . Using a third subinterval
. Using a third subinterval ![[-B, B]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7930e5eb60b08c9c79feaad5515fd0f2_l3.svg "Rendered by QuickLaTeX.com") for the whole middle part would imply that this has to be an even function, thus of the form
for the whole middle part would imply that this has to be an even function, thus of the form  .
.  . According to the first derivative condition we would have
. According to the first derivative condition we would have  , thus
, thus  . According to the second derivative condition we would have
. According to the second derivative condition we would have  thus
thus  thus
thus  Since subintervals of equal length are required, this is not adequate.
Since subintervals of equal length are required, this is not adequate.![[-B,0]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-c59f71baddbaa30543b1b944b6f50145_l3.svg "Rendered by QuickLaTeX.com") four conditions are given to determine the four coefficients of the cubic function.
four conditions are given to determine the four coefficients of the cubic function. and
and  , so the subintervals are
, so the subintervals are ![[-2,-1], [-1, 0], [0,1], [1,2]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-8c248cc84442b6ce9d8537b03ba10fb4_l3.svg "Rendered by QuickLaTeX.com") . The function can be choosen as
. The function can be choosen as![\[f(x)= \begin{cases} 0 &\text{for } x \le -2\\ (x+2)^3&\text{for } -2 < x \le -1 \end{cases}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-a79f1ad5e116a795d2904680555c3fb5_l3.svg "Rendered by QuickLaTeX.com")
![\[f(x)=a+b(x+1)+c(x+1)^2+d(x+1)^3\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-60abf1bcd8b868329e6e18c77fb6d68f_l3.svg "Rendered by QuickLaTeX.com")
![\[f(-1)=1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-50cd8f9adfb3dffd8229cd8bdb600540_l3.svg "Rendered by QuickLaTeX.com")
![\[f'(-1)=3\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7cf33adcb11b81ef5d745734a1530b8e_l3.svg "Rendered by QuickLaTeX.com")
![\[f''(-1)=6\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-4461fd6ce1b6137c0fd9127e2646359a_l3.svg "Rendered by QuickLaTeX.com")
![\[f'(0)=0\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-c1b4b8ca1bb4565af9498a89d1343753_l3.svg "Rendered by QuickLaTeX.com")
 ,
,  ,
,  and
and![\[0=f'(0)=b+2c+3d=9+3d\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-8e441ece29deb593535ba3452aee6aaf_l3.svg "Rendered by QuickLaTeX.com")
 .
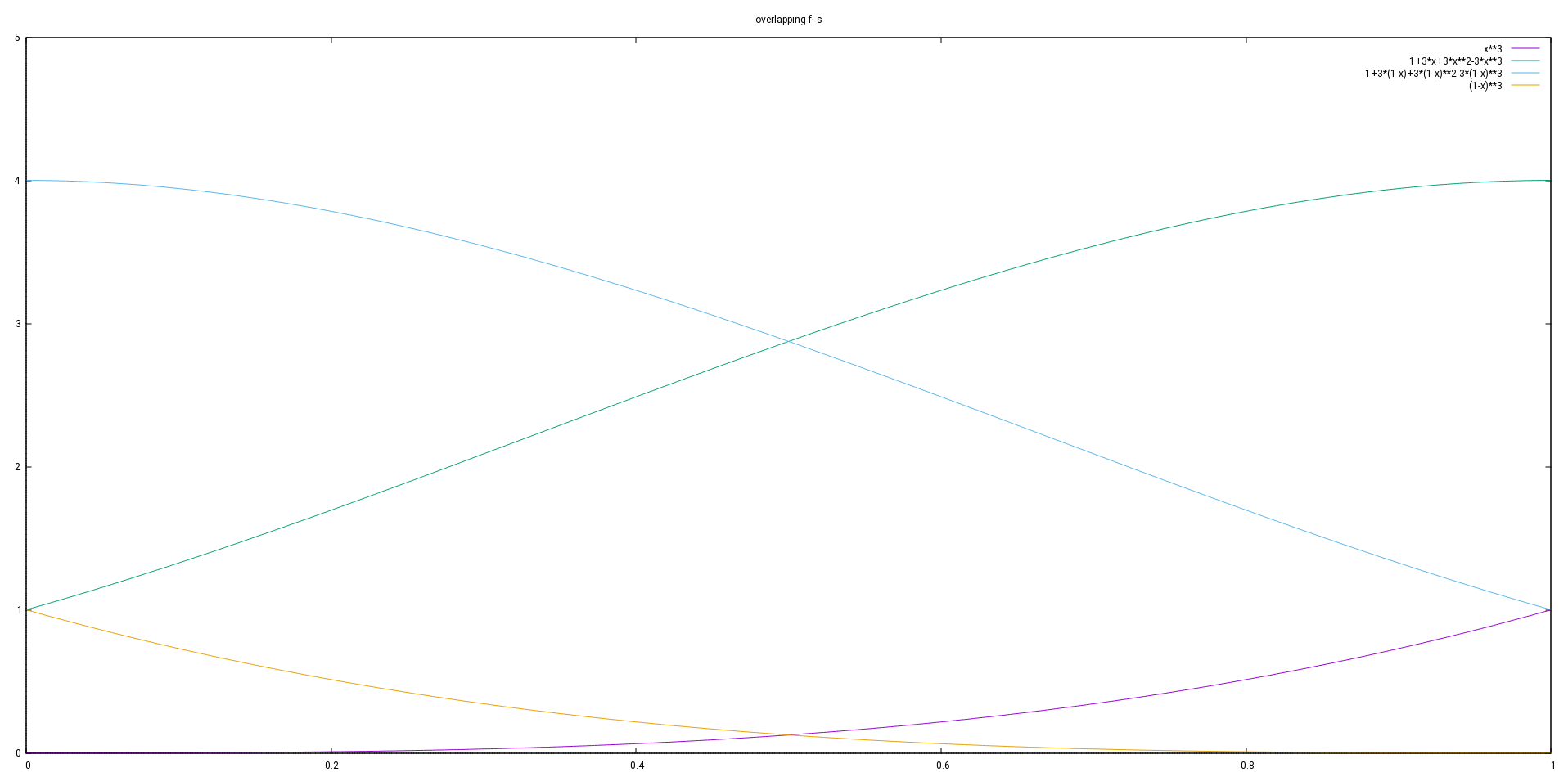
.![\[(5)\thickspace f(x)= \begin{cases} 0 &\text{for } x \le -2\\ (x+2)^3&\text{for } -2 < x \le -1\\ 1+3(x+1)+3(x+1)^2-3(x+1)^3&\text{for } -1 < x \le 0\\ 1+3(1-x)+3(1-x)^2-3(1-x)^3&\text{for } 0 < x \le 1\\ (2-x)^3&\text{for } 1 < x \le 2\\ 0&\text{for } x > 2 \end{cases}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-3016030c2282c86f17796da83d572dab_l3.svg "Rendered by QuickLaTeX.com")
 for
for  . For readability purposes we define
. For readability purposes we define![\[x_{j}=x_0+jh\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-97ec24e7534a83386241ba47d28d3f5d_l3.svg "Rendered by QuickLaTeX.com")
 and
and  .
.![\[f_i(x)=f\left(\frac{x-x_i}{h}\right) \text{ for } i=-1,\ldots,n+1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-97cf02e77f5cf9de178083b2f6a4a067_l3.svg "Rendered by QuickLaTeX.com")
 .
. alone. If it is true for
alone. If it is true for  it is also true for
it is also true for  , because
, because![\[f_i\left(x_i+\frac{3}{2}h\right) >0\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1df4b41feba4d395bca5c7b9b6939fce_l3.svg "Rendered by QuickLaTeX.com")
![\[\bigwedge_{j=-1}^{i-1}f_j\left(x_i+\frac{3}{2}h\right)=0\text{.}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-6646e1d1389098fe5d29501c211ef056_l3.svg "Rendered by QuickLaTeX.com")
![\[\{f_{-1},\ldots,f_{n+1}\}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-316e27da42a2d48a02137edfec022533_l3.svg "Rendered by QuickLaTeX.com")
![\[(6)\thickspace g(x) = \sum_{i} a_i f_i(x)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-d507403f3f41bebca4fae179cd78b083_l3.svg "Rendered by QuickLaTeX.com")
 :
:![\[(4a)\thickspace S(a_{-1},\ldots,a_{n+1}) = \sum_{j=1}^N \left(g\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1a630c92c038952615dd2784a664c4df_l3.svg "Rendered by QuickLaTeX.com")
![\[= \sum_{j=1}^N ( \sum_{i} a_i f_i(\xi_j)-\eta_j)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-aea6e68753f0a767a60d6445bb6e91b3_l3.svg "Rendered by QuickLaTeX.com")
![\[(4b) \thickspace\bigwedge_{k=-1}^{n+1} 0 &= \frac{\partial}{\partial a_k}\sum_{j=1}^N \left(g\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-d3c4f4b24686b37c9920d4223b0a8f7f_l3.svg "Rendered by QuickLaTeX.com")
![\[= \frac{\partial}{\partial a_k}\sum_{j=1}^N \left( \sum_{i} a_i f_i\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-2e6ed162c1bb99de05d819a2ca32e5b7_l3.svg "Rendered by QuickLaTeX.com")
![\[=\sum_{j=1}^N \left(2 f_k\left(\xi_j\right)\left( \sum_{i} a_i f_i\left(\xi_j\right)-\eta_j\right)\right)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-707f6ba540cec8d75ff113be4ad3db08_l3.svg "Rendered by QuickLaTeX.com")
![\[=2\sum_{i} a_i \sum_{j=1}^N f_k\left(\xi_j\right)\left( f_i\left(\xi_j\right)-2\sum_{j=1}^N \f_k\left(\xi_j\right)\eta_j\right)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-542698ed80f083d5804008bf19a3fc4e_l3.svg "Rendered by QuickLaTeX.com")
![\[\sum_{i=-1}^{n+1} a_i \sum_{j=1}^N f_k\left(\xi_j\right) f_i\left(\xi_j\right) = \sum_{j=1}^N f_k\left(\xi_j\right)\eta_j\thickspace\text{ ~ for }k=-1,\ldots,n+1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7cb052ba2c92ee43cab7c2a29862a1e5_l3.svg "Rendered by QuickLaTeX.com")
![\[f(x)=a+b(x-A)+c(x-A)^2+d*(x-A)^3.\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-45cb4fe7dcf9ccbb4ec91697f9d6df6b_l3.svg "Rendered by QuickLaTeX.com")
 are given and we want to find a function such that for all of these points we have
are given and we want to find a function such that for all of these points we have  (interpolation) or
(interpolation) or  (approximation). Most often we say that we want on average
(approximation). Most often we say that we want on average  to be as small as possible and for whatever reasons usually the
to be as small as possible and for whatever reasons usually the  and
and  might be useful.
might be useful.