Happy Easter!

IT Sky Consulting GmbH
Happy Easter!
When programming in Java, it is kind of part of the language to write classes with attributes and equip these attributes with „getters“ and „setters“. You could do otherwise, but you just don’t. But some criticism is of course allowed. Even if it only applies to the design of future languages or to minor improvements in the Java language.
The reason for using this pattern is of course that we do not want to impose inner implementation details of classes, but just interfaces. The implementation can change, for example the getter can caclulate the attribute instead of just returning it. Or it might possible happen in the future, that it will be calculated. And the setter can perform sanity checks or even to some adjustments of dependent attributes. Or, most interestingly, the setter can be omitted in an approach towards immutability. Now there are whole big categories of classes in many projects, that never ever contain any business logic. It is an architectural decision, to put all business logic into certain places. This does not sound like the idea of the OO-paradigm, actually Martin Fowler considers even it an antipattern, but it is done and it makes sense for classes that contain data in interface definitions. So, a typical java application has tons of layers, each with the almost same data classes, mostly without any business logic, because the business logic resides in classes that are reserved to contain business logic. Basically procedural programming, but with cool frameworks and OO because written in an OO-language. Data is copied multiple times between the different layers. One of the layers is the DB-layer and the classes are managed by hibernate. Now interesting questions arise, if hibernate goes through the getters and setters or directly to the attributes. The latter seems to be more common and it allows for a work-around for an important Oracle Bug.
Now „stupid“ getters and setters make the code larger, harder to maintain and harder to read. They can be generated automatically by IntelliJ, Eclipse, Perl Scripts or Emacs-Lisp code and I have always done it that way. But when changing code it becomes more difficult at some point.
There is also a subtle issue in terms of the name space. It is highly unusual to start attribute names with „get“ or „set“, but it would be possible and create a lot of confusion. Since getters for boolean attributes often start with „is“ or even „has“ instead of „get“, this problem does actually exist there, because people like to naturally name some boolean attributes with names like „isNew“ or „hasEngine“ and then the getters become „isIsNew“, „isHasEngine“ or something like that. Also some funny effects can occur when all capital abreviations like HTML or XML are part of the attribute name. This causes some pain, but of course, we live with it…
Interestingly Java creates „internal“ getters and setters for each attribute and they are called when accessing attributes and they are used as hooks for Hibernate in some setups. So there is seemingly an indirection too much, because the getter that we write calls the internal getter, so why not just make get… an alias for the internal getter? This does not seem to be a problem, because the optimization of Java is so fantastic and it is fair to assume that such a common case is really well optimized. So, do not mess around with this for the sake of optimazation, unless you really know what you are doing and run serious benchmarks for this.
Now having a look at other languages shows that things can be done in a better way without losing the original benefit of getters and setters.
Ruby, Scala and C# show that this is possible. The getters are just named like we would name an attribute, so we can use something like
point.x
to access the x-coordinate of the point. In Scala it is quite a thing that the classes should be immutable, so the setters go away anyway. C# and Ruby allow setters to be defined in such a way that they look like an assignment:
point.x = 9
Just two final remarks:
Do not write Unit-Tests for trivial getters and setters, but do write Unit-Tests for getters and setters that are not trivial, but have at least a bit of logic. And configure your sonarqube to be happy with that.
And in terms of documentation, if the project encourages documentation, agree on where to write the documentation and write it in this one place. For example always write javadoc for the getter and never for the attribute or the other way round. And for tons of class hierarchies that are more or less isomorphic, agree in which layer the documentation goes and write it only there, unless another layer happens to actually differ in a non-trivial way on this attribute. Having documentation for basically the same thing more than once is usually a bad idea. The burden of maintenance will increase and it will be outdated even faster than usual javadoc.
A new Java framework Functionativity has been announced today. I will totally change the way we work and attract all people who are now using other langauges like Scala, Kotlin, Clojure, Ruby, Perl, C#, PHP, Python, JavaScript … to move to Java, just to be able to use this new framework and gain more efficiency than ever before within a week after the transition.
Funcionativity is installed only on the developers machine. The program is written there in any style and automatically transformed into highly functional modern java code that allows for high scalability and runs on any device without any installation of software and without any testing. The new super sandbox prevents any bugs from actually being executed. With artificial intelligence the framework finds out what was meant to be programmed, even if there are some inaccuracies and bugs in the program and it will correct itself. The web interface will design itself automatically to the current taste and cooperate design and create the maximal user friendly UEX. It is using only HTML, and with a trick it can put functionality that used to require JavaScript into pure executable HTML. So it works even with very old browsers and JavaScript turned off and provides a rich and highly responsive user interface that minimized network traffic between the browser and the server.
There are integrations to combine Functionativity code with existing legacy frameworks and of course migration scripts to transform code written in other langauges into Java code that works with Functionativity…
We are talking about system administration and system engineering for Linux. Most of this also works more or less the same on Unix, but this is today much less relevant. It is even possible to do some of these things on MS-Windows, but that is another story… So just assume for the time being OS=Linux. Or wait for the next article in two weeks, if that is not relevant for you….
In the good old days system administration meant logging into the server and doing something there. Of course good system engineers wrote scripts in Bash, Ruby, Perl or Python and got things done more efficiently. When we were maintaining 1000 vending machines of a public transport company, we wrote scripts that ran on one Linux-machine in our office and iterated through a whole list of machines to perform a task on them. Usually one, then another one, then five or so and at some point the rest.
It is not totally gone, it is still necessary to log into the machine to do things that are not yet automated, that are not worth while automating or that simply did not work as desired. Or to check if things did work as desired.
But with tools like ansible it is now possible to do what was done with these scripts in the old days. Ideally the idea is to describe the end state, for example a certain:
– We want a certain user to be present. If it is present, nothing is done, if not, the user is created.
– We want a certain file system to be mounted on a certain mount point. Same idea….
– We want a certain package to be installed. If it is missing, it is installed.
The files that describe the desired outcome are in a directory tree and this is called a playbook. We can think of it as a high level scripting langauge, just a bit like SQL, where we also describe the outcome and not how to get there. And as always, there are ways to fall back to python and bash where the built in features are not sufficient.
Ideally, ansible playbooks, as they are called, are idempotent. That means, they can be exucuted as many times as we want without creating harm. That makes it much easier to update 1000 hosts. We can just try the update on 1, 2, 5, 10, 50 and 100 and then on all and it does not matter, if we actually just give the whole list in the last step or if we by mistake have the same host multiple times. It does matter a bit, because the whole thing becomes slower, the more hosts we have in the list. But still it is no big risk of messing things terribly up.
But this depends on how the playbooks are written. So the goal of writing idempotent playbooks needs to be taken care of the achieve this. In cases where standard ansible features are used, this is usually the case. But when the playbooks are using our own extensions or calling python or bash scripts, we are on our own and need to keep an eye on this or deal with the fact that the playbook is not idempotent.
Now usually there is a file called inventory, that contains „all“ hosts. This needs to be provided. Often the hosts in the file are put into groups and certain steps apply only to one group. Now the actual installation can and usually should be limited to a subset of this „all“, for example when we are installing on a test system and not on production servers. It is possible to limit this to a group, a single host, a short list of hosts or to the hosts found in another file (not the inventory). With some simple scripts it is for example possible, to run the playbook on the next n hosts that have not been processed so far or to split up work with a colleague.
And the playbooks should of course be managed by a source code management system, for example git.
We often read that code reviews are a good idea.
Bugs can be found, people are encouraged to keep to team standards, know-how is spread in both directions and code becomes more maintainable. Also it helps sharing responsibility.
So basically the time spent for the code reviews is well spent and increases the long term efficiency.
But there are some things to observe concerning code reviews.
I have basically seen two variants. In one case a meeting was held and a certain portion of code was known in advance and discussed in the meeting.
The way I have seen much more often was that someone worked on a branch and before merging that branch into the main branch someone else had to review it. The outcome could be that it was merged into the main branch by the reviewer, that the reviewer gave green light to merge it to the developer or that there were minor finding which could be fixed by the reviewer or the developer prior to immediate merging without further review or there could be larger findings that would require a second review.
In an organization that was still not using git they worked with svn on the main branch and somehow the reviewer had to find out which changes belonged to the review. This was a bit of a pain, but other than that the end results were similar to the process using git.
Some issues need to be observed. I will use antipatterns to clarify them.
In one organization the code reviews were done in meetings. The organization had some kind of „review master“ who participated in these meetings. And he had the power to organize such review meetings whenever he wanted. His understanding of review was to bully people, to show them, how stupid they were and how good he was. So the result was, that such meetings were a nightmare for many developers and they felt bad already during the week before. Then the review meetings were horrible and after that the developer whose code was reviewed was depressed for a week or two. So of course depending on the developer, whose code was reviewed, it was just a slightly unpleasant meeting or it meant serious loss of productivity of one person down to almost zero for a few weeks. No, it did not happen to me, but I saw it happen.
Do not do that. Code review is about improving and learning and not about making people bad or judging about people. Some people even do not like it, if review results are communicated by word where others may hear it. Email or chat or whatever is available is preferred. Better respect that.
Also in a place where meetings were held, someone mentioned in the review that he does not like identifiers with more than 12 characters or so. Now it was a Java program and it is just common practice to have very long identifiers in Java, like XyzCombinerControllerFactory or something like that. It caused a long discussion, which is worth discussing at some point, but in this case it was kind of off-topic. So it is important to find an agreement on general standards on which to base the review. And to respect them during the review, even if you disagree. Of course common sense should always be part of the story.
In another case, there was a change in one layer, which was very important and useful, but in that step it was constrained to one layer. The reviewer was against this change and made the point that he would revert the whole thing, because it does not cover all layers. Since that organization was working with svn, even the change in one layer and the merge afterwards is a big deal, but doing all layers at once would have been unreasonable. Again, there was a lack of agreement on the basis.
Another frequently observed issue is that some reviewers like to make a point of issues like how curly braces are put or how spaces are used or other things that could very well be dealt with by a software automatically. I would like to see a setup, where each developer may choose his formatting convention and on commit everything is automatically converted to a common team standard. So this is not even worth the effort of manual editing, but nobody works like this. But at least we have tools like Sonarqube that can discover issues automatically and it is a waste of time for humans.
Then apart from agreeing that everything is fine, there are different possible outcomes and I think it is important to use them. So I see these possibilities:
The goal of spline approximation has already been explained in the previous article „Spline Approximation (Introduction)„.
This article will cover the mathematics behind this approximation and develop an approach. If you do not care about the mathematics, just skip this article and read the Spline Approximation (Cookbook)“, that will come soon.
We have points
![\[(x_0, y_0), (x_1, y_1), \ldots, (x_n, y_n)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-32c169ca08aa1d049a00f14b699f82cb_l3.svg "Rendered by QuickLaTeX.com")
(0.1) ![\[x_0 < x_1 < x_2 < \ldots < x_n \]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-0a3c30648d4199dfa4cd9c99a5af847f_l3.svg "Rendered by QuickLaTeX.com")
and want a function f such that
![\[(1)\thickspace \bigwedge_{i=0}^n f(x_i) = y_i\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-11ef934755ef20d90672f2cdd4528ed0_l3.svg "Rendered by QuickLaTeX.com")
and f is continuous. Usually the requirement goes further, so the first and second derivative should also be continuous too.
The way this is accomplished is by defining cubic polynomials  on each interval
on each interval ![[x_j, x_{j+1}]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-9170d120d3644c7c3e080b0a1b07097a_l3.svg "Rendered by QuickLaTeX.com") such that
such that
![\[(2)\thickspace \bigwedge{j=1}^{n-1} f'_{j-1}(x_j)=f'_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-50060ad10581e671c571893722219ca1_l3.svg "Rendered by QuickLaTeX.com")
![\[(3)\thickspace \bigwedge{j=1}^{n-1} f''_{j-1}(x_j)=f''_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1b3995a80dc50ee928088055a9e715bd_l3.svg "Rendered by QuickLaTeX.com")
Now this gives us  unknowns and together with the initial condition
unknowns and together with the initial condition  equations. So this is underdetermined, which is usually resolved by adding two more or less arbitrary conditions. A lot of material can be found about this in the internet, in papers and in books.
equations. So this is underdetermined, which is usually resolved by adding two more or less arbitrary conditions. A lot of material can be found about this in the internet, in papers and in books.
Now a more interesting case is that we actually have much more given points than spline intervals. So we have interval borders at points
![\[x_0,\ldots,x_n\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-459d49cc184ac7cf03b0250358be0af2_l3.svg "Rendered by QuickLaTeX.com")
and we have given pairs
![\[(\xi_1,\eta_1), \ldots, (\xi_N, \eta_N)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-6c65f742eac20d06d9ae99bd3c9c7a41_l3.svg "Rendered by QuickLaTeX.com")
with  much larger than
much larger than  . The exact condition will become clear later, but for the time being it should be assumed, that is meant to be much larger than . The values
. The exact condition will become clear later, but for the time being it should be assumed, that is meant to be much larger than . The values  may contain duplicates, but in that case the number of different values for should also be much larger than .
may contain duplicates, but in that case the number of different values for should also be much larger than .
Btw. this is nothing new. Papers about this topic exist, but it is not as commonly found on the internet as the interpolation.
From here onwards, it is assumed, that the intervals all have the same length, i.e. there is some positive real number  such that
such that  for all
for all  .
.
So we want the conditions (2) and (3) to be fullfilled and a weaker condition
![\[(1a)\thickspace \bigwedge_{j=1}^{n-1} f_{j-1}(x_j)=f_j(x_j)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1475a72285388d1115fa6269fdead5c4_l3.svg "Rendered by QuickLaTeX.com")
and we want  to be „somewhat close“ to
to be „somewhat close“ to  for all points
for all points  . More precisely it should be as close as possible on „average“, where the quadratic mean is used as „average“. That is common practice, allows for smooth formulas and works. To just minimize the quadratic mean, taking the square root and dividing by can be ommitted. So this can be made explicit by requiring the sum of the squares of the differences to be minimal i.e.
. More precisely it should be as close as possible on „average“, where the quadratic mean is used as „average“. That is common practice, allows for smooth formulas and works. To just minimize the quadratic mean, taking the square root and dividing by can be ommitted. So this can be made explicit by requiring the sum of the squares of the differences to be minimal i.e.
![\[(4)\thickspace \sum_{i=1}^N (f(\xi_i)-\eta_i)^2 \text{ is minimal}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1ae2ac7ff8a4251beb4a66401e4ee123_l3.svg "Rendered by QuickLaTeX.com")
Btw. this can be done perfectly well with complex valued functions, we just need to replace the squares by the squares of the absolute values. So on the „ -side“ we can have complex numbers. Allowing complex numbers on the „
-side“ we can have complex numbers. Allowing complex numbers on the „ -side“ is a bit more involved, because being differentiable twice implies that the function would be holomorphic, so combining different functions is impossible. And even complex valued functions would become non continuous at the glue lines if we simply apply them to the whole complex plain. So, for the time being, real numbers are assumed.
-side“ is a bit more involved, because being differentiable twice implies that the function would be holomorphic, so combining different functions is impossible. And even complex valued functions would become non continuous at the glue lines if we simply apply them to the whole complex plain. So, for the time being, real numbers are assumed.
Now the valid spline functions on the given set of intervals obviously form a vector space. Conditions (1a), (2) and (3) remain valid when we multiply by a constant or add two such functions. Having parameters and  independent conditions, its dimension should be
independent conditions, its dimension should be  . This can be proved by induction. For
. This can be proved by induction. For  any cubic polynomial (of degree
any cubic polynomial (of degree  ) can be used. These form a 4-dimensional vectorspace. Assuming that for subintervals the valid spline functions form a vector space of dimension , then for
) can be used. These form a 4-dimensional vectorspace. Assuming that for subintervals the valid spline functions form a vector space of dimension , then for  subintervals the additional subinterval
subintervals the additional subinterval ![[x_n, x_{n+1}]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-85c5feea1d5351a816d202be772d3379_l3.svg "Rendered by QuickLaTeX.com") is added. In this subinterval, the function can be expressed as
is added. In this subinterval, the function can be expressed as
![\[f(x)=a+b(x-x_n)+c(x-x_n)^2+d(x-x_n)^3\text{.}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-eca131d3d6f98c8881f85a0811eab1f7_l3.svg "Rendered by QuickLaTeX.com")
Conditions (1a), (2) and (3) already fix the values for  ,
,  and
and  , while
, while  can be choosen freely. Thus the dimension is exactly one higher and the assumption is proved.
can be choosen freely. Thus the dimension is exactly one higher and the assumption is proved.
Now a basis for this vector space should be found. Ideally functions that are only non-zero in a small range, because they are easier to handle and easier to calculate.
This can be accomplished by a function that looks like this:
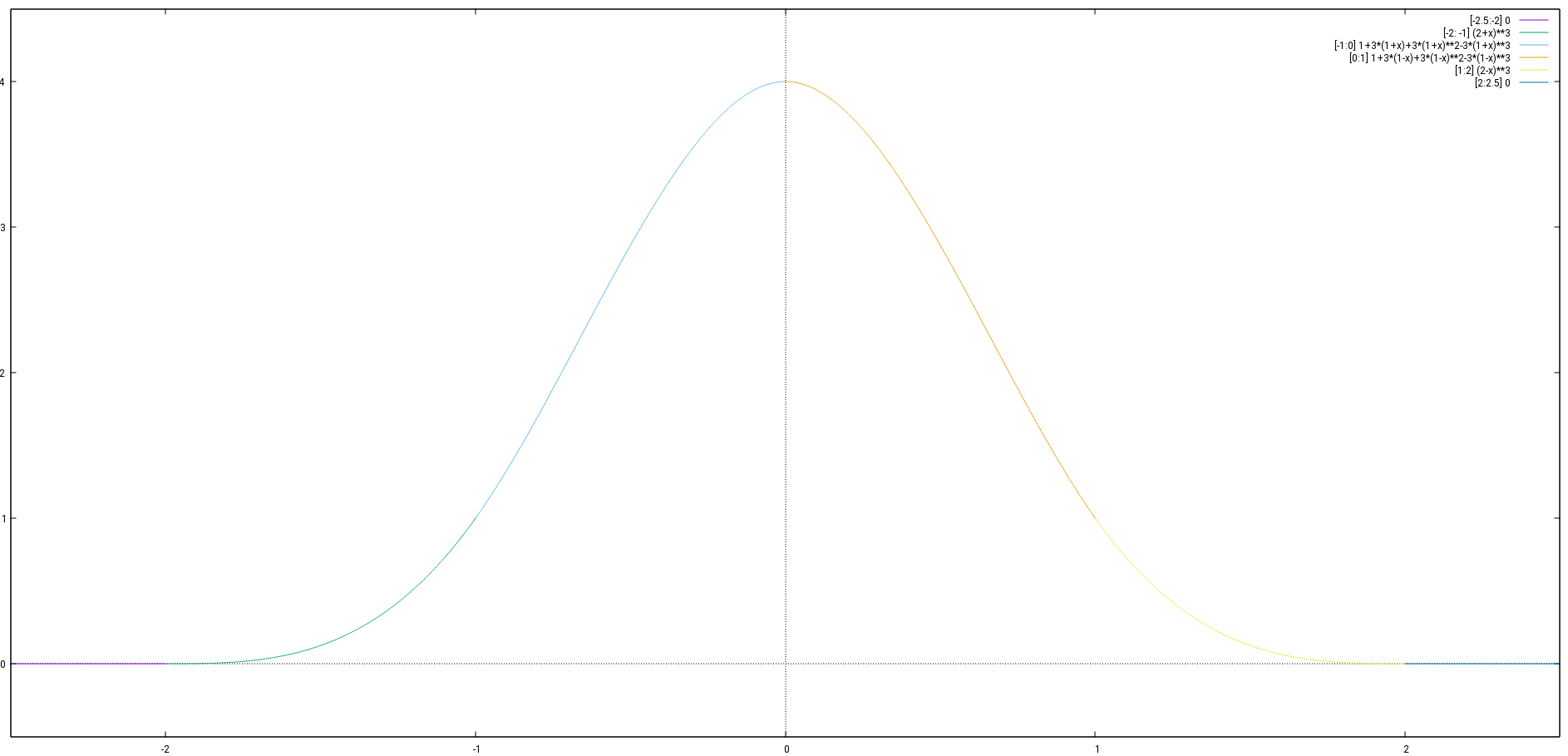
Note that this is not the Gaussian function curve, which never actually becomes zero. The function we are looking for should actually be 0 outside of a given range. So assuming it is  for
for  and
and  for
for  for some constant
for some constant  . This implies that the first and second derivative are
. This implies that the first and second derivative are  for
for  . So in the subinterval starting at
. So in the subinterval starting at  it needs to be a cubic polynomial of the form
it needs to be a cubic polynomial of the form  . So further subintervals are needed to return to . For reasons of symmetry there should be a subinterval ending at
. So further subintervals are needed to return to . For reasons of symmetry there should be a subinterval ending at  in which the function takes the form
in which the function takes the form  . Using a third subinterval
. Using a third subinterval ![[-B, B]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7930e5eb60b08c9c79feaad5515fd0f2_l3.svg "Rendered by QuickLaTeX.com") for the whole middle part would imply that this has to be an even function, thus of the form
for the whole middle part would imply that this has to be an even function, thus of the form  . could be determined as
. could be determined as  . According to the first derivative condition we would have
. According to the first derivative condition we would have  , thus
, thus  . According to the second derivative condition we would have
. According to the second derivative condition we would have  thus
thus  thus
thus  Since subintervals of equal length are required, this is not adequate.
Since subintervals of equal length are required, this is not adequate.
Using a total of four subintervals actually works. In this case for the subinterval ![[-B,0]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-c59f71baddbaa30543b1b944b6f50145_l3.svg "Rendered by QuickLaTeX.com") four conditions are given to determine the four coefficients of the cubic function.
four conditions are given to determine the four coefficients of the cubic function.
For readability it will be assumed that  and
and  , so the subintervals are
, so the subintervals are ![[-2,-1], [-1, 0], [0,1], [1,2]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-8c248cc84442b6ce9d8537b03ba10fb4_l3.svg "Rendered by QuickLaTeX.com") . The function can be choosen as
. The function can be choosen as
![\[f(x)= \begin{cases} 0 &\text{for } x \le -2\\ (x+2)^3&\text{for } -2 < x \le -1 \end{cases}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-a79f1ad5e116a795d2904680555c3fb5_l3.svg "Rendered by QuickLaTeX.com")
Now
![\[f(x)=a+b(x+1)+c(x+1)^2+d(x+1)^3\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-60abf1bcd8b868329e6e18c77fb6d68f_l3.svg "Rendered by QuickLaTeX.com")
needs to be defined in [-1, 0] such that
![\[f(-1)=1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-50cd8f9adfb3dffd8229cd8bdb600540_l3.svg "Rendered by QuickLaTeX.com")
![\[f'(-1)=3\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7cf33adcb11b81ef5d745734a1530b8e_l3.svg "Rendered by QuickLaTeX.com")
![\[f''(-1)=6\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-4461fd6ce1b6137c0fd9127e2646359a_l3.svg "Rendered by QuickLaTeX.com")
![\[f'(0)=0\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-c1b4b8ca1bb4565af9498a89d1343753_l3.svg "Rendered by QuickLaTeX.com")
Thus  ,
,  ,
,  and
and
![\[0=f'(0)=b+2c+3d=9+3d\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-8e441ece29deb593535ba3452aee6aaf_l3.svg "Rendered by QuickLaTeX.com")
Thus  .
.
So the prototype function is
![\[(5)\thickspace f(x)= \begin{cases} 0 &\text{for } x \le -2\\ (x+2)^3&\text{for } -2 < x \le -1\\ 1+3(x+1)+3(x+1)^2-3(x+1)^3&\text{for } -1 < x \le 0\\ 1+3(1-x)+3(1-x)^2-3(1-x)^3&\text{for } 0 < x \le 1\\ (2-x)^3&\text{for } 1 < x \le 2\\ 0&\text{for } x > 2 \end{cases}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-3016030c2282c86f17796da83d572dab_l3.svg "Rendered by QuickLaTeX.com")
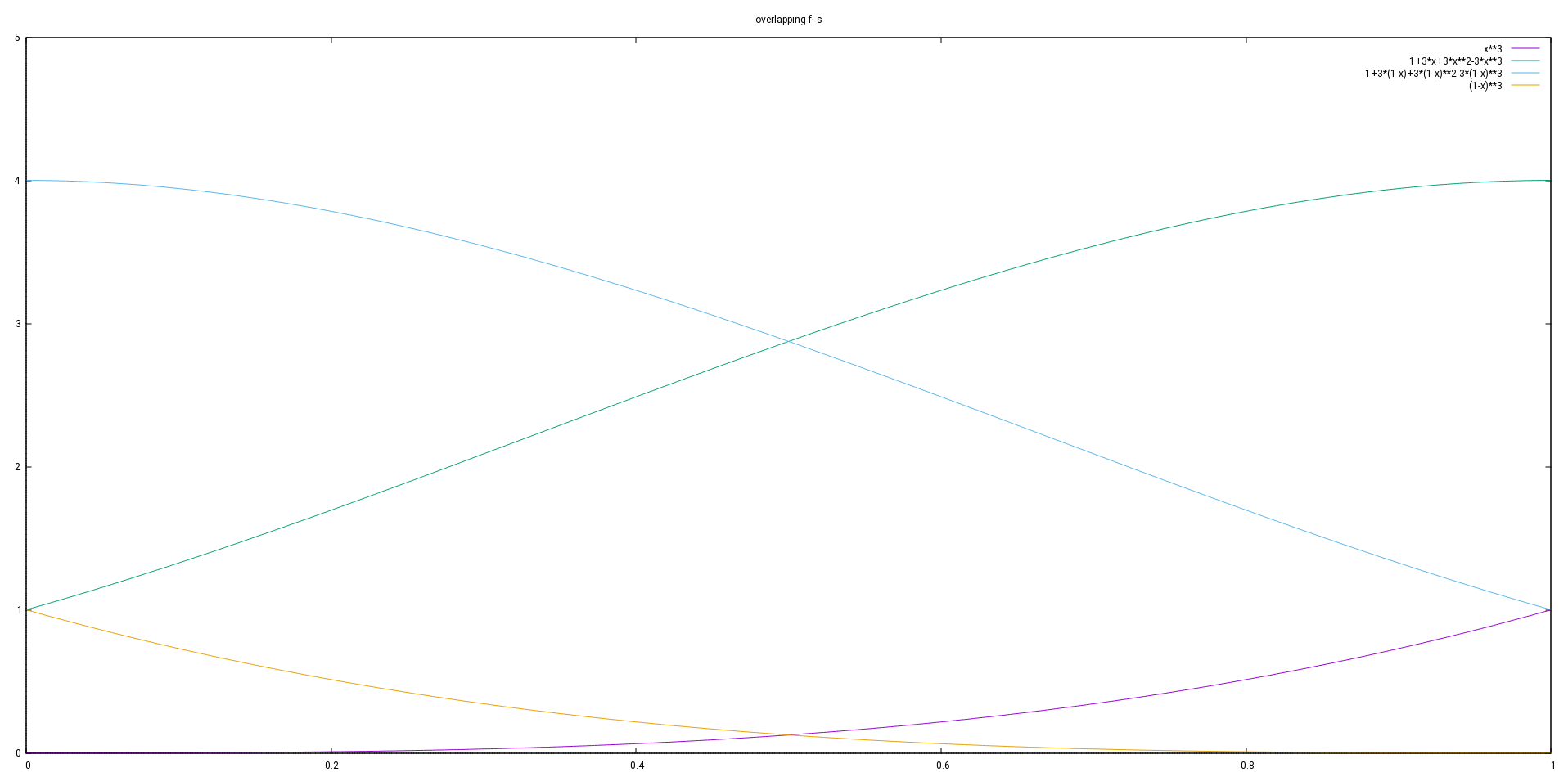
A base for this vector space can be found using functions  for
for  . For readability purposes we define
. For readability purposes we define
![\[x_{j}=x_0+jh\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-97ec24e7534a83386241ba47d28d3f5d_l3.svg "Rendered by QuickLaTeX.com")
even for negative  and
and  .
.
The functions are defined such that such that
![\[f_i(x)=f\left(\frac{x-x_i}{h}\right) \text{ for } i=-1,\ldots,n+1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-97cf02e77f5cf9de178083b2f6a4a067_l3.svg "Rendered by QuickLaTeX.com")
These functions fulfill conditions (1a), (2) and (3), because they inherit that from  .
.
By induction it can be proved that they are linear independent. It is true for  alone. If it is true for
alone. If it is true for  it is also true for
it is also true for  , because
, because
![\[f_i\left(x_i+\frac{3}{2}h\right) >0\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1df4b41feba4d395bca5c7b9b6939fce_l3.svg "Rendered by QuickLaTeX.com")
and
![\[\bigwedge_{j=-1}^{i-1}f_j\left(x_i+\frac{3}{2}h\right)=0\text{.}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-6646e1d1389098fe5d29501c211ef056_l3.svg "Rendered by QuickLaTeX.com")
Since
![\[\{f_{-1},\ldots,f_{n+1}\}\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-316e27da42a2d48a02137edfec022533_l3.svg "Rendered by QuickLaTeX.com")
contains exactly elements, it is a vector space basis.
That means that we are searching for a function
![\[(6)\thickspace g(x) = \sum_{i} a_i f_i(x)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-d507403f3f41bebca4fae179cd78b083_l3.svg "Rendered by QuickLaTeX.com")
such that the minimality condition (4) holds.
This is accomplished by filling (6) into (4) and calculating the partial derivatives with respect to each  :
:
![\[(4a)\thickspace S(a_{-1},\ldots,a_{n+1}) = \sum_{j=1}^N \left(g\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-1a630c92c038952615dd2784a664c4df_l3.svg "Rendered by QuickLaTeX.com")
![\[= \sum_{j=1}^N ( \sum_{i} a_i f_i(\xi_j)-\eta_j)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-aea6e68753f0a767a60d6445bb6e91b3_l3.svg "Rendered by QuickLaTeX.com")
Thus
![\[(4b) \thickspace\bigwedge_{k=-1}^{n+1} 0 &= \frac{\partial}{\partial a_k}\sum_{j=1}^N \left(g\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-d3c4f4b24686b37c9920d4223b0a8f7f_l3.svg "Rendered by QuickLaTeX.com")
![\[= \frac{\partial}{\partial a_k}\sum_{j=1}^N \left( \sum_{i} a_i f_i\left(\xi_j\right)-\eta_j\right)^2\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-2e6ed162c1bb99de05d819a2ca32e5b7_l3.svg "Rendered by QuickLaTeX.com")
![\[=\sum_{j=1}^N \left(2 f_k\left(\xi_j\right)\left( \sum_{i} a_i f_i\left(\xi_j\right)-\eta_j\right)\right)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-707f6ba540cec8d75ff113be4ad3db08_l3.svg "Rendered by QuickLaTeX.com")
![\[=2\sum_{i} a_i \sum_{j=1}^N f_k\left(\xi_j\right)\left( f_i\left(\xi_j\right)-2\sum_{j=1}^N \f_k\left(\xi_j\right)\eta_j\right)\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-542698ed80f083d5804008bf19a3fc4e_l3.svg "Rendered by QuickLaTeX.com")
So it comes down to solving the linear equation system
![\[\sum_{i=-1}^{n+1} a_i \sum_{j=1}^N f_k\left(\xi_j\right) f_i\left(\xi_j\right) = \sum_{j=1}^N f_k\left(\xi_j\right)\eta_j\thickspace\text{ ~ for }k=-1,\ldots,n+1\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-7cb052ba2c92ee43cab7c2a29862a1e5_l3.svg "Rendered by QuickLaTeX.com")
This can be solved using a variant of the Gaussian elimination algorithm. Since this is a numerical problem, it is important to deal with the issue of rounding. Generally it is recommended choosing the pivot element wisely.
In this case the approach is chosen to iterate through the columns. For each column the line is chosen, in which the element in that column has the largest absolute value relative to the cubic mean of the absolute values of the other entries in the line.
When actually using the spline function a lot, it is probably a good idea to consolidate the linear combinations of different s within each subinterval into a cubic polynomial of the form
![\[f(x)=a+b(x-A)+c(x-A)^2+d*(x-A)^3.\]](https://brodowsky.it-sky.net/wp-content/ql-cache/quicklatex.com-45cb4fe7dcf9ccbb4ec91697f9d6df6b_l3.svg "Rendered by QuickLaTeX.com")
This can be based on the starting point of the interval or the end point or some point in the middle, probably the arithmetic mean of the interval borders. These choices of A have some advantages, because it makes the terms that need to be added smaller in terms of absolute value. Since the accurate end result is anyway the same, this helps avoiding rounding errors, that can go terribly wrong when adding (or subtracting) terms with large absolute values where the result is much smaller than the terms. So the arithmetic mean of the subinterval borders might be the best choice.
The actual formulas and a program will be added in one or two articles in the near future.
We sometimes encounter a situation where a number of points with coordinates  are given and we want to find a function such that for all of these points we have
are given and we want to find a function such that for all of these points we have  (interpolation) or
(interpolation) or  (approximation). Most often we say that we want on average
(approximation). Most often we say that we want on average  to be as small as possible and for whatever reasons usually the quadratic mean. The most simple and well known approximation is probably linear regression, where a straight line is found that tries to approximate the points. This can be extended to other function, for example polynomials of a fixed maximum order. For something that is supposed to be periodic, linear combinations of functions of the form
to be as small as possible and for whatever reasons usually the quadratic mean. The most simple and well known approximation is probably linear regression, where a straight line is found that tries to approximate the points. This can be extended to other function, for example polynomials of a fixed maximum order. For something that is supposed to be periodic, linear combinations of functions of the form  and
and  might be useful.
might be useful.
Now it may not be easy to express the whole extent by one function. So the interval, in which the x-coordinates lie, might be subdivided into subintervals and linear regression or whatever is being used can be performed in each subinterval separately. This results in a polygon-like curve or worse in a curve that „jumps“ at the interval borders. This can well be good enough and it is relatively easy to implement. With the additional constraint, that it should be continuous at the interval borders, it becomes a bit more difficult.
Now there is some preference for smooth curves. For example it might be desirable that the function is continuous (i.e. it does not jump at interval boarders) and even its first and second derivative should be continuous. This roughly resembles a mechanical spline as it was used in the old days for drawing and constructing. Kind of an elastic ruler.
This is where Splines are often used to interpolate a smooth curve that passes through some given points. More precisely cubic splines, but the concept is of course more general. A lot of material can be found on the internet about spline interpolation.
But they can also be used for approximation. So we want a curve that is smooth and that approximates our given points and that is expressible as a simple third degree polynomial in each subinterval.
Just to make it clear, the subintervals are not used as a „divide et impera“ strategy, but we consider all the points at once, just give ourselves the freedom to have different functions in different subintervals to get a combined function that behaves better than polynomials of very high degree. We do need to think also a bit about the inaccuracy of floating point arithmetic. So polynomials of degree three are still somewhat precise within the subinterval, but a higher order polynomial that is applied to a large interval will become less accurate with normal floating point arithmetic („double“).
I will leave this as a starting point for thinking. In some of the next articles, the spline approximation will be derived mathematically and then there will be a cookbook how to use it programmatically. My advice is to experiment with the implementation and its parameters until you are confident that it give sufficiently precise result, have a look at the math behind it to understand the question of the precision or have someone else have a look. With floating point arithmetic it is always a bad idea just to program something that looks right and totally ignore the rounding errors of floating point arithmetic, that can have huge impact on the result.
There is a lot of material on spline interpolation on the internet. On spline approximation there have been some papers, but very little can be found on the internet.
A followup article covering the mathematics behind spline approximation has been written.
Postal addresses seem to be easy:
– Name and/or Company
– Street and/or PostBox
– ZIP Code
– Municipality
– Country
This is true in Germany or Switzerland and a few other countries. I would like to add, that in some large buildings it can be a good idea to add the apartment number, but these buildings are rare in these two countries and the name is really almost always sufficient.
For relational databases please keep in mind, that these fields may get just a bit or even a lot longer than we anticipated. US-ZIP-Codes are now something like NY-11713-5532. And others may be longer. How long are names, street names and names of villages and towns? Even the country part, which seems to be relatively easy, brings some challenges. Countries like Switzerland and Germany and Canada are no problem. But what about semi-independent countries like Guernsey, Jersey, …? And what about areas, that are de-jure part of another country, but de-facto an independent country? Or an independent country that is not accepted by each country? There are lists of countries that we can find and usually they include also the „semi-independent“ and „semi-accepted“ countries. But it is a good idea to check if the list is complete enough for our purpose. I would not recommend to define it yourself.
But now the other parts of the address: If we want to describe the location where a person lives, and this person does not live in a housing area, but for example in a nomadic life style, it becomes a bit harder. Or we might observe a different number of lines for the address. Or even that streets are not named consistently and the only relyable address is a postbox. Many countries do not write the names on the door and on the letterbox, but just an apartment number. So this number with some word for „apartment“ that is understood by the local post officer with possibly limited language skills is needed. Also in some countries there are a lot of buildings for „streetname 3053A“, so we need to add the building number also.
My point is, that postal addresses are not as easy as it might seem. So I recommend to do some research in the internet to find a library or a documentation that handles this or can be used as a basis instead of trying to invent a new wheel that will probably be incomplete and suffer from its insufficiencies at some point. It is sometimes more important to recognize which seemingly trivial problems are actually harder than being able to invent solutions for such problems. We should invest our energy on solving problems that have not been solved with publicly available documentations or even libraries and that make up our business. In this case the actual implementation is rather trivial, but the specification of the requirements is the hard part, so it is enough to find some useful documentation for this. It might of course be sufficient to handle only for example French addresses, if the system will never be dealing with foreign addresses, but the experience shows that at least some thinking about what it means to extend the system later are a good idea.
And please, handle too long entries properly instead of displaying a stack trace on the end users screen or even providing a spot to attack the server.
Un an nou fericit! — Happy new year! — Срећна нова година! — Frohes neues Jahr! — Onnellista uutta vuotta! — С новым годом! — Gullukkig niuw jaar! — FELIX SIT ANNUS NOVUS — ¡Feliz año nuevo! — Feliĉan novan jaron! — عام سعيد — Щасливого нового року! — Gott nytt år! — Bonne année! — Καλή Χρονια! — Felice anno nuovo! — Godt nytt år!
This was generated with JavaScript using Rhino:
a = ["Frohes neues Jahr!",
"Happy new year!",
"Gott nytt år!",
"¡Feliz año nuevo!",
"Bonne année!",
"FELIX SIT ANNUS NOVUS",
"С новым годом!",
"عام سعيد",
"Felice anno nuovo!",
"Godt nytt år!",
"Gullukkig niuw jaar!",
"Feliĉan novan jaron!",
"Onnellista uutta vuotta!",
"Срећна нова година!",
"Un an nou fericit!",
"Щасливого нового року!",
"Καλή Χρονια!"];
b = a.map(function(x) { return Math.floor(1000000000 + Math.random()*1000000) + " " + x; });
b.sort();
c = b.map(function(x) { return x.replace(/^\d+\s+/, ""); });
print(c.join(" — "));
¡Feliz Navidad! — καλά Χριστούγεννα! — Buon Natale! — З Рiздвом Христовим! — クリスマスおめでとう ; メリークリスマス — Natale hilare! — Merry Christmas! — ميلاد مجيد — Hyvää Joulua! — С Рождеством! — Joyeux Noël! — God Jul! — Feliĉan Kristnaskon! — Crăciun fericit! — God Jul! — Frohe Weihnachten! — Срећан Божић! — Prettige Kerstdagen!

This was generated by a bash script. I am using Perl instead of sed, but not for program logic:
#!/bin/bash
set -e
mkfifo /tmp/tmp_pipeA-$$
mkfifo /tmp/tmp_pipeB-$$
cat << EOTXT |head -18 > /tmp/tmp_pipeA-$$ &
С Рождеством!
Hyvää Joulua!
καλά Χριστούγεννα!
Buon Natale!
Prettige Kerstdagen!
З Рiздвом Христовим!
Merry Christmas!
Срећан Божић!
God Jul!
¡Feliz Navidad!
ميلاد مجيد
クリスマスおめでとう ; メリークリスマス
Natale hilare!
Joyeux Noël!
God Jul!
Frohe Weihnachten!
Crăciun fericit!
Feliĉan Kristnaskon!
EOTXT
od -x /dev/urandom \
|head -18 \
|perl -p -e ’s/^\d+\s//;‘ > /tmp/tmp_pipeB-$$ &
paste /tmp/tmp_pipeB-$$ /tmp/tmp_pipeA-$$ \
|sort \
|cut -f 2 \
|perl -p -e ’s/\n/ — /g;‘ \
|perl -p -e ’s/ — $/\n/;‘
rm -f /tmp/tmp_pipeA-$$
rm -f /tmp/tmp_pipeB-$$